편의상 pandas -> pd, numpy -> np로 표기한다.
1. CREATE
1-1. CSV 파일 LOAD
df=pd.read_csv("./emp2.csv") #csv파일 불러서 df변수에 저장
df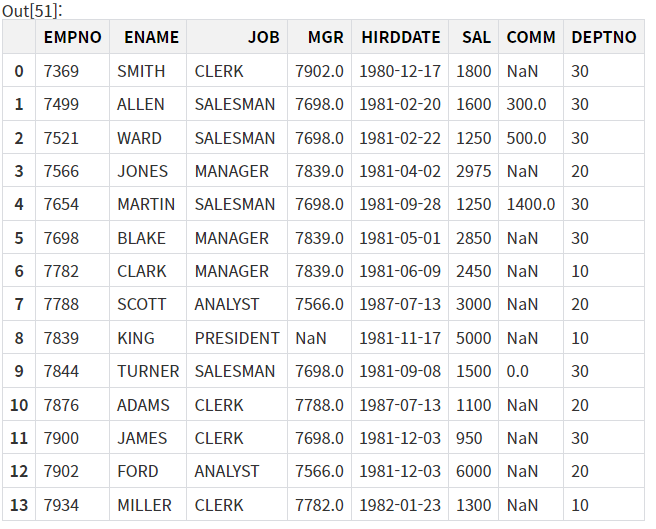
1-2. 리스트로 담아서 DF 만들기
pandas.DataFrame(data=리스트명, index=행이름리스트(or None), columns=열이름리스트(or None))
# data=None, -> 가져와야할 데이터 (리스트)
# index: Axes | None = None, (row 명 데이터) (추가안하면 0,1,2...)
# columns: Axes | None = None, (column명 데이터) (추가안하면 0,1,2...)
# dtype: Dtype | None = None,
list_data = [[8000,'CHOI','CLERK','7782','1995-05-31',2000,np.NaN,10],
[8001,'KIM','CLERK','7783','1995-04-20',1000,np.NaN,10]]
col_list = ['EMPNO','ENAME','JOB','MGR','HIRDDATE','SAL','COMM','DEPTNO']
df2=pd.DataFrame(data=list_data, columns=col_list)
#columns = 데이터프레임명.columns로 다른DF의 칼럼 가져올 수 있음
df2
1-3. DF 카피하기
복사본df명 = df.copy() => 조건 추가해서 원하는 데이터만 복사 가능
ex. df[df['JOB']=='MANAGER'].copy()
# create table empcp as (select empno, ename, sal, job from emp where deptno=30)
empcp = df[df['DEPTNO']==30][['EMPNO','ENAME','SAL','JOB']].copy() ##카피
empcp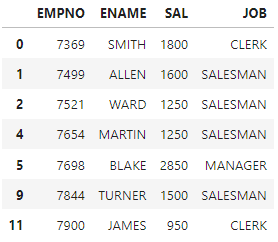
2. INSERT
2-1. 리스트를 DF로 바꾸고 INSERT
리스트를 바로 append() 하려고 하면 컬럼명이 달라서 결과가 이상하게 나오니까
리스트를 같은 컬럼명의 DF로 바꿔준 다음에 append()하는 것이 좋다.
앞에서 리스트로 만든 df2를 기존 df에 추가해주겠다.
list_data = [[8000,'CHOI','CLERK','7782','1995-05-31',2000,np.NaN,10],
[8001,'KIM','CLERK','7783','1995-04-20',1000,np.NaN,10]]
df2=pd.DataFrame(data=list_data, columns=df.columns)
df=df.append(df2, ignore_index=True)
df
#ignore_index=True 를 사용하지 않으면 행 이름이 겹치는 현상 발생
#(ex. 0,1,2,3,4..12,0,1)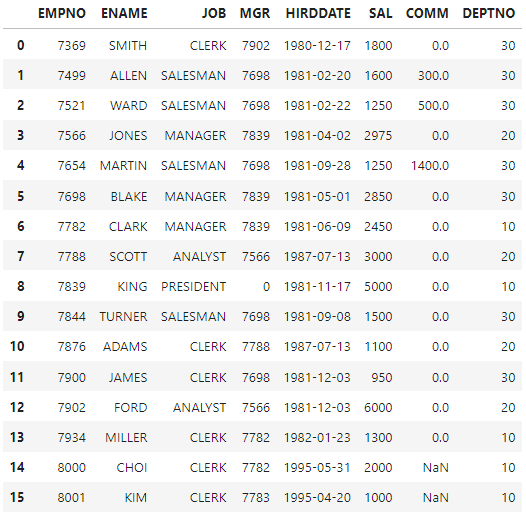

2-2. loc을 사용해서 INSERT
df명.loc['집어 넣을 행 이름'] = [리스트]
df.loc['원하는 행 이름'] = [8000,'CHOI','CLERK','7782','1995-05-31',2000,np.NaN,10]
#현재 행의 최대값 +1의 행에 추가
idx = df.index.values.max()+1
df.loc[idx] = [8000,'CHOI','CLERK','7782','1995-05-31',2000,np.NaN,10]
#마지막 행에 추가
idx = df.iloc[-1].name + 1
df.loc[idx] = [8000,'CHOI','CLERK','7782','1995-05-31',2000,np.NaN,10]3. SELECT
3-1. 칼럼별로 호출 df[칼럼명]
#select empno, enmae, sal from emp
df[['EMPNO','ENAME','SAL']]
3-2. array처럼 [행,열]로 호출 iloc()
#[[1,2,3행],[0,1,2열]] 호출
df.iloc[[1,2,3],[0,1,2]]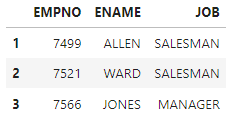
#[0,1,2,3행],0~3열]
#**마지막 번호까지 출력함 ==> 통상 사용하는 슬라이싱이랑 다름
df.iloc[[0,1,2,3],0:3]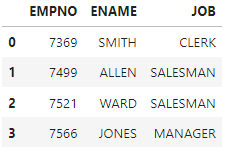
3-3. 로우명, 칼럼명으로 호출 loc()
#[[행이름][열이름]]
df.loc[[0,1,2,3],['EMPNO','ENAME','JOB']]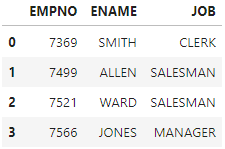
df.loc[[0,1,2,3],'EMPNO':'JOB']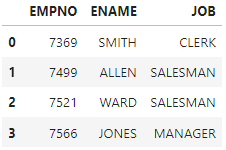
4. WHERE
4-1. 단일 조건일 경우
df[조건][칼럼] 이나 df[칼럼][조건] 형식으로 출력 조건을 설정할 수 있다.
df.loc[조건, 칼럼]으로도 사용 가능 -- df.loc[df명[칼럼명]조건, 컬럼명]
#select empno, ename, sal from emp where deptno=10;
df[['EMPNO','ENAME','SAL','DEPTNO']][df['DEPTNO']==10]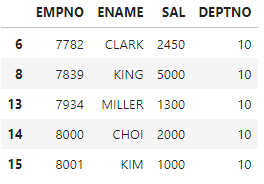
df[df['DEPTNO']==10][['EMPNO','ENAME','SAL','DEPTNO']]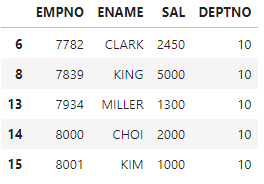
4-2. 조건이 여러 개일 경우
df[(df[]조건) &/| (df[]조건)] ** ()처리 반드시 해야함
#select * from emp where deptno=30 and job='SALESMAN'
df[(df['DEPTNO']==30) & (df['JOB']=='SALESMAN')]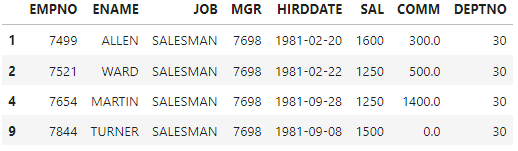
#select * from emp where job='MANAGER' or job='SALESMAN'
df[(df['JOB']=='MANAGER') | (df['JOB']=='SALESMAN')]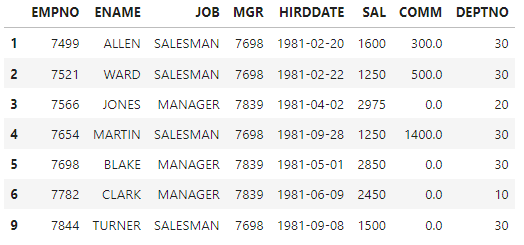
select job, deptno from emp where deptno=30 and (job='SALESMAN' or deptno=10)
df[((df['DEPTNO']==30) & (df['JOB']=='SALESMAN'))|(df['DEPTNO']==10)][['JOB','DEPTNO']]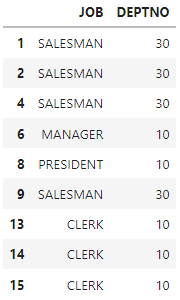
5. 서브쿼리
5-1. 단일행 서브쿼리
Value값에 변수를 넣어서 비교한다
#select ename, job from emp where job=(select job from emp where empno=7782)
x=df[df['EMPNO']==7782]['JOB'].values[0]
#values[]값은 인덱스 번호인데 단일행은 하나니까 0해주면 됨
x
df[df['JOB']==x][['ENAME','JOB']]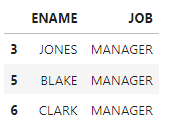
5-2 다중행 서브쿼리
SQL에서 사용하는 in은 -> df[].isin() 함수로 사용한다.
x_list=df[df['DEPTNO']==10]['JOB'].values
#다중행은 여러개의 값이 출력이네 values 뒤에 []를 붙이면 안됨
x_list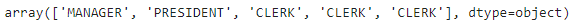
#select ename,job from emp where job in (select job from emp where deptno=10)
df[df['JOB'].isin(x_list)][['ENAME','JOB']]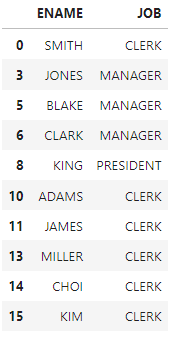
6. 연산 ( ||, +, -, *, / )
- NaN에는 어떤 연산을 해도 NaN이다
- db: nvl(col,0) -> python : df.fillna(0) df[컬럼].fillna(0)
- db: 컬럼 is not null, 컬럼 is null -> python : df.isna() df.notna() df.isnull() df.notnull()
- df.astype() 캐스팅
6-1. ( || ) 연산
SQL의 || 연산은 문자들을 그대로 이어서 합치는 연산이다.
Python 상에서 ||연산은 문자형식의 컬럼 + 문자형식의 컬럼으로는 + 연산이 문제없다.
#문자형식 + 문자형식
new_col=df['ENAME']+df['JOB'] #컬럼을 담을 변수 생성
df['new_col']=new_col #위에서 담은 변수를 데이터로 df에 새로운 컬럼 생성
df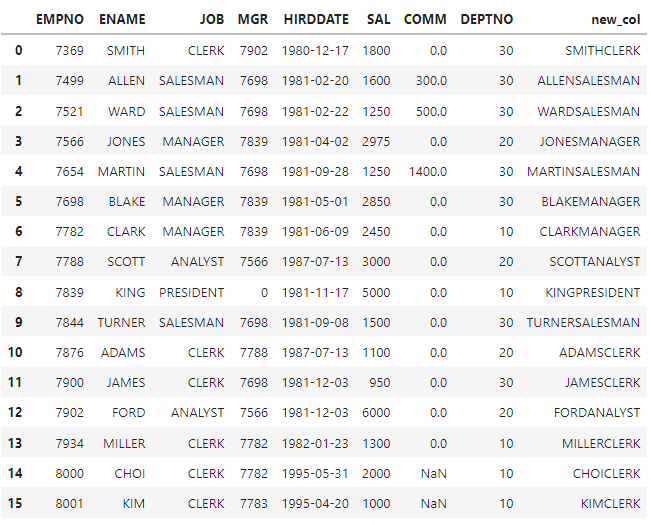
하지만 문자 + 숫자 형식의 경우 .astype()를 통해 형식을 바꿔줘야함
new_col=df['ENAME']+df['EMPNO'].astype(str) #str 형식으로 변환
df['new_col']=new_col
df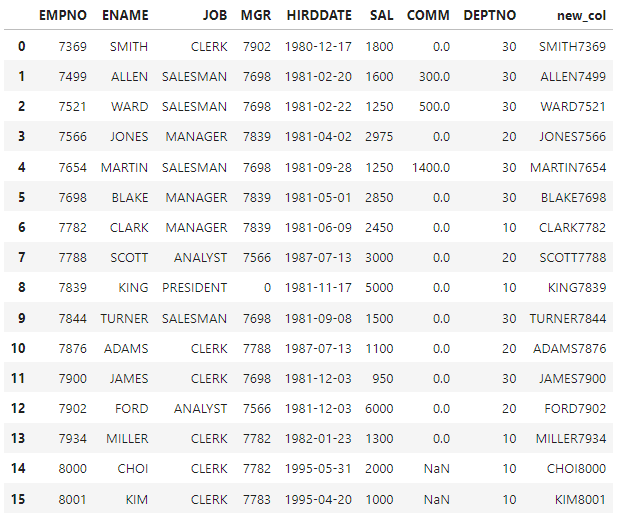
6-2. 사칙연산
숫자형식 과 숫자형식의 경우 (+, -, *, / )기호로 사칙연산이 가능함
new_col2=df['SAL']+df['COMM'].fillna(0) # NaN값을 0으로 만든다 (Nvl함수)
df['SAL+COMM']=new_col2.astype(int) #int로 캐스팅
df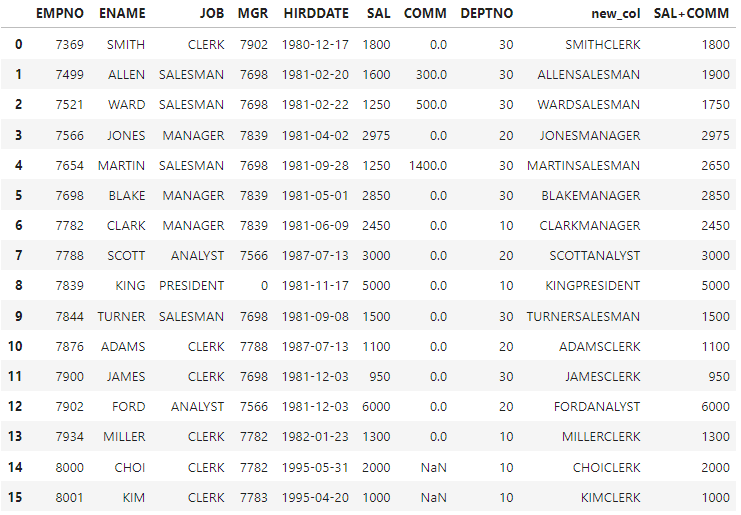
7. GROUP 함수
- db : count() min() max() sum() avg()
- df : value_counts() min() max() sum() mean() ... std() var()
7-1. 일반적인 사용법
df명.groupby('그룹지을 컬럼명')['함수 적용할 컬럼'].함수()의 형식으로 사용한다.
value_counts()의 경우 df명[칼럼명].value_counts로 그룹 없이 사용할 수 있음
#부서별 사원수 출력
#select deptno, count(1) from emp group by deptno;
df.groupby("DEPTNO")["EMPNO"].count()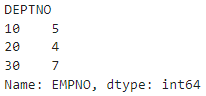
df.groupby("DEPTNO")["SAL"].mean()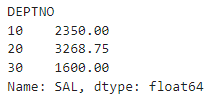
여러 가지 그룹 함수를 출력하고 싶을 때에는
.agg(['함수이름1','함수이름2'...])을 붙인다.
#select deptno, min(sal), max(sal), sum(sal), avg(sal) from emp group by deptno
df.groupby("DEPTNO")["SAL"].agg(["min","max","sum","mean"])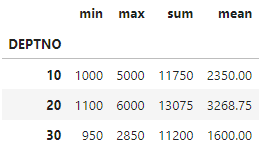
각기 다른 칼럼에 다른 함수를 적용하고 싶을 때,
딕셔너리를 통해서 사용하는 방법인데
컬럼이름(키 값)이 같으면 오류가 나니까 주의하자.
#select deptno, max(sal), min(comm) from emp group by deptno
mydict = {"SAL":"max", "COMM":"min"} #컬럼이름(키 값)이 같으면 안됨
df.groupby("DEPTNO").agg(mydict)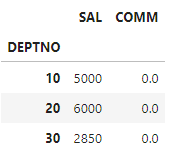
df[df조건]과 합쳐서 WHERE 조건과 연계하여 사용가능하다.
#select deptno, min(sal), max(sal), sum(sal), avg(sal) from emp
#where deptno =10
#group by deptno
df[df['DEPTNO']==10].groupby("DEPTNO")[["SAL"]].agg(["min","max","sum","mean"])
8. UPDATE
8-1. 특정 행 UPDATE 하기
loc, iloc 함수를 이용하여 특정 행을 지정하고 데이터 값을 리스트 형식으로 삽입하여 UPDATE가능
empcp.iloc[1] = [7499,'ALLEN22',1800,'MANAGER']
empcp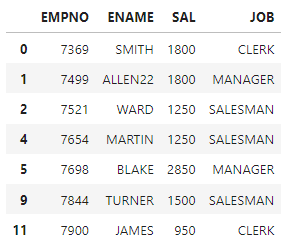
9. DELETE
9-1. 행(로우) 지우기
- 행 한줄 지우기
- empcp.drop(index = [행1, 행2], axis=0)
empcp.drop(index=11, axis=0) #-- inplace=True를 사용해야 실제로 지워짐 -> 사용안하면 삭제한 견본만 보임
#empcp.drop(index=11, axis=0, inplace=True)
#empcp = empcp.drop(index=11, axis=0) 이렇게도 지우기 가능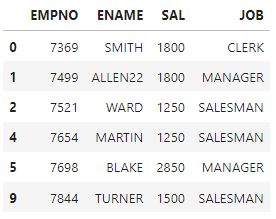
9-1. 열(칼럼) 지우기
- 열(컬럼) 지우기
- empcp.drop(['컬럼','컬럼'], axis=1)
empcp.drop('job', axis=1) ##칼럼 지우기 (axis = 1)
#-- inplace=True를 사용해야 실제로 지워짐 -> 사용안하면 삭제한 견본만 보임
#empcp.drop('job', axis=1, inplace=True)
#empcp=empcp.drop(['job','sal','ename'], axis=1)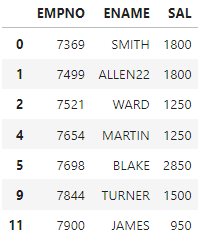
10. UNION
11. JOIN
- pandas.merge(left DF명, right DF명, on(left,right), how='조인방식')
- how : {'left','right','outer','inner'}--> {왼쪽기준outer,오른쪽기준outer,풀outer,이너[defalt]}
- 키가 동일하면 : on
- 좌 우 프레임의 조인할 키가 다를 경우 : left_on, right_on
기준열 이름이 같을 때:
pd.merge(left, right, on = '기준열', how = '조인방식')
기준열 이름이 다를 때:
pd.merge(left, right, left_on = '왼쪽 열', right_on = '오른쪽 열', how = '조인방식')11-1. 활용할 테이블
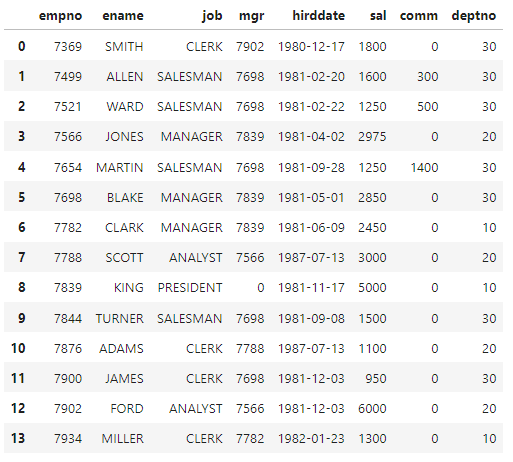
11-2. 다른 DF와 조인
#DEPT 테이블 생성하기
dept_list = [[10,'ACCOUNTING','NEW YORK'],[20,'RESEARCH','DALLAS'],
[30,'SALES','CHICAGO'],[40,'OPERATIONS','BOSTON']]
dept_col = ['deptno','dname','loc']
dept_df = pd.DataFrame(data=dept_list, columns=dept_col)
dept_df#select * from emp e, dept d where e.deptno=d.deptno(+)
df_join2 = pd.merge(df,dept_df, on='deptno',how='right')
df_join2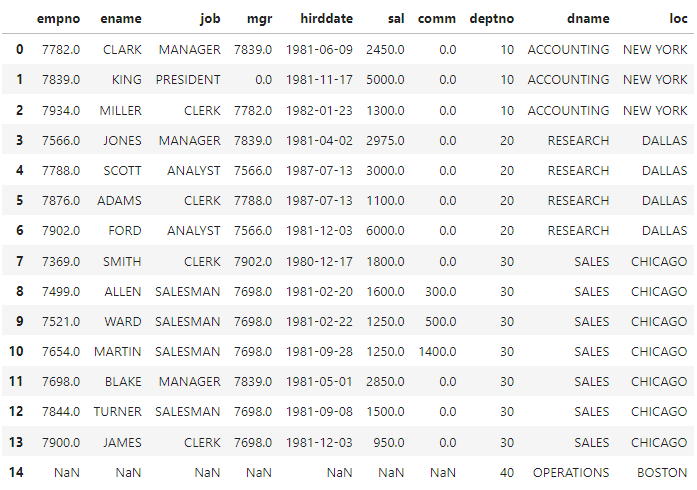
11-3. 셀프조인
#select e1.*, e2.empno, e2.ename from emp e1, emp e2 where e1.mgr=e2.empno
df_join = pd.merge(emp,emp[['empno','ename']], left_on='mgr',right_on='empno',how='left')
df_join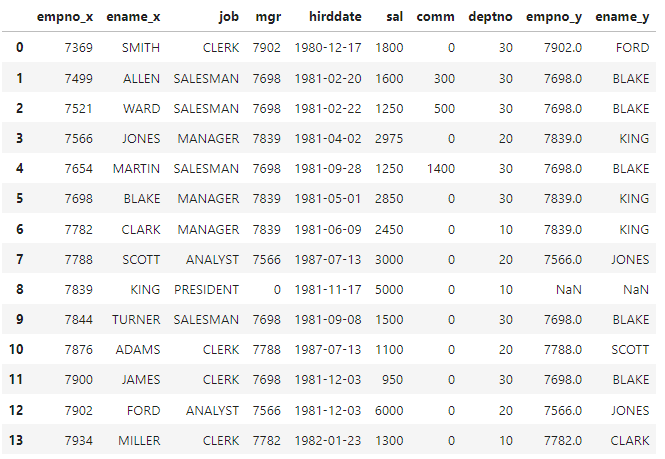
12. ORDER BY
by = [컬럼]
ascending = True -> 오름차순
ascending = False -> 내림차순
#하나의 컬럼 기준으로 정렬
DF명.sort_values(by=[컬럼명], ascending=True)
##여러 개의 컬럼 기준으로 정렬
DF명.sort_values(by=['컬럼명1','컬럼명2'], ascending=True)
#여러 개의 컬럼 각기 다른 방식으로 정렬
DF명.sort_values(by=['컬럼명1'], ascending=True).sort_values(by=['컬럼명2'], ascending=False)'Python > 데이터 분석' 카테고리의 다른 글
| (데이터 분석) 파이썬 - Pandas DataFrame SQL처럼 활용하기(Join,Union) (0) | 2022.01.10 |
|---|---|
| (데이터 분석) 파이썬 - Pandas DataFrame SQL처럼 활용하기(CRUD) (0) | 2022.01.07 |
| (데이터 분석)파이썬 - Pandas_dataframe (0) | 2022.01.06 |
| (데이터 분석)파이썬 - Pandas DataFrame, Numpy array (0) | 2022.01.05 |
| (데이터 분석) Pandas 가이드북 링크 (0) | 2022.01.05 |




댓글